|
XIDEK
|
|
Four Ways to Write an InterpreterIntroductionAs is the case in most engineering problems, the answer to the question, "What is the best way to write a script interpreter?", is "it depends."Traditionally, the most challenging part of writing a script interpreter has been parsing the script. Considerations of utility, performance, ease of use and other significant factors have frequently been sacrificed in an effort to simplify the parsing problem, so that the answer to the above question has sometimes unfortunately been, "Whatever way you can manage to do it!" Parsing becomes much easier when you have the use of a powerful parser generator such as AnaGram, to the extent that it almost ceases to be an issue for consideration. The interpreter designer now has the freedom to consider tradeoffs among various architectural options and make choices to complement the overall project strategy. Among the issues one might consider in determining what architecture to use are the following:
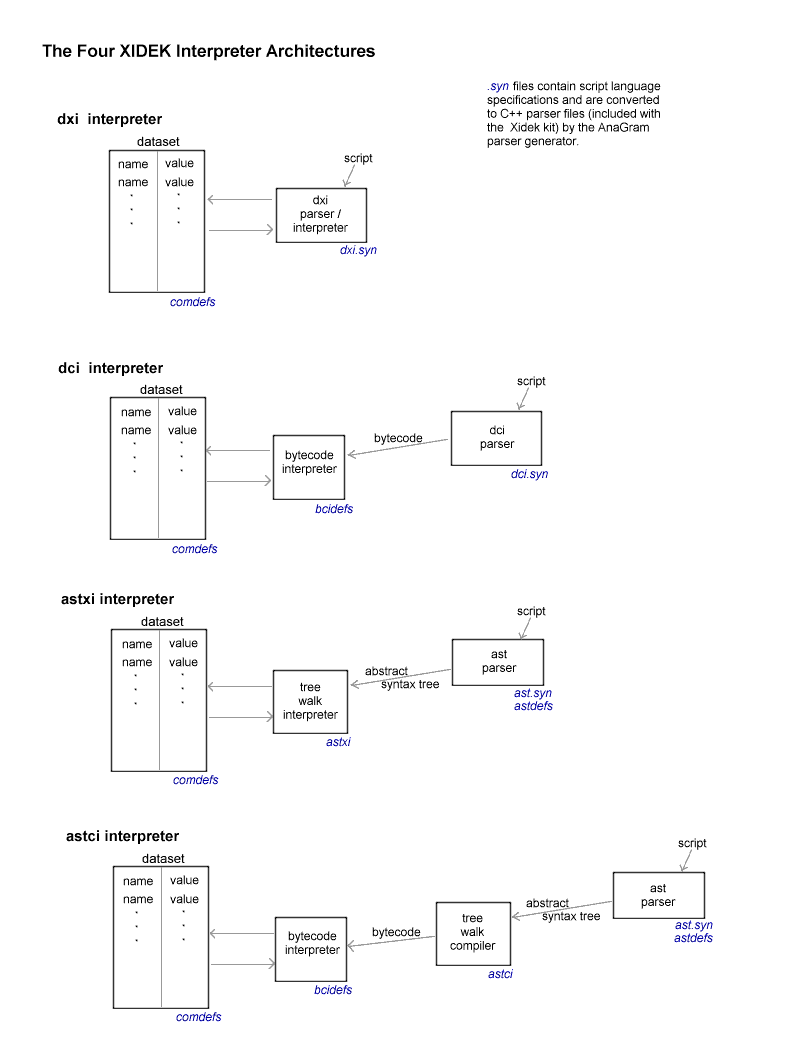
The following diagram illustrates schematically the four basic architectures. The code modules that implement each component are identified in blue.
The eight baseline interpreters have been designed to facilitate comparisons between language implementations and interpreter architecture. The languages implemented provide the basic constructs needed to implement almost any interpreter: recognition of variable names and constants, evaluation of expressions, and execution of conditional and loop statements. The languages do not, however, provide for several common features of programming languages: subscripts, structures and function definitions. Since these features can be implemented in any of a number of ways, it was felt that they should not be incorporated into the baseline languages. Instead, they have been implemented as examples of extensions to the interpreters. Any of the eight interpreters, or any of the extended interpreters, can be taken as a starting point for developing a custom interpreter. As discussed below, the interpreters have been designed with extensibility as a major design criterion. To help in understanding how the interpreters work, reference documents have been provided which describe the implementation details of each interpreter architecture. We now consider the four architectures in terms of their advantages and disadvantages.
1. Direct Executiondxi: Direct Execution Interpreter ReferenceOstensibly, the simplest interpreter architecture is one which performs the indicated operations immediately, as the parse progresses. This first approach is exemplified by two "direct execution interpreters", dxi, one for each of the two baseline languages CLL and PLL. Although the direct execution architecture is suitable for very simple languages and has the advantage of requiring a minimum of support code, conditional and loop constructs can cause implementation problems.The need to execute these constructs at parse time noticeably complicates parsing, since the effective input to the parser, i.e., the sequence of characters actually parsed, is not the same as the actual text of the input script. To execute a while loop, for example, requires parsing the loop afresh for each iteration of the loop. Backing up and reparsing a portion of the input is not a standard part of the principles which underly formal parsing. Although it is possible to rewrite the syntax of the while and for loops so that they accurately reflect the true input, the resulting syntax is so complex that it does not serve as a useful guide to further work. Accordingly, the direct execution interpreter has been set up to handle loops by making recursive calls to the interpreter. This is a very useful technique, easily extensible, which can be used to deal with any number of difficult parsing problems. In spite of these peculiarities, direct execution is an easy architecture to extend, even if the extension requires additional conditional or looping constructs, which, as a practical matter, is quite unlikely. Direct execution is sometimes considered "inefficient" because loops must be parsed over and over, once for each iteration of the loop. The extra time required, however, may turn out in practice to be insignificant. Obviously the usage of the particular language must be considered carefully from this point of view.
2. Tree Executionastxi: Tree Execution Interpreter ReferenceA second way to approach the interpreter problem is to decouple parsing from execution by building an abstract syntax tree as the script is parsed. The script can then be executed by traversing the tree. This approach has the benefit of noticeably simpler parsing than direct execution, but it has the disadvantage of requiring four modules where the direct execution parser had only two. In addition to the common definitions module used by the direct execution interpreter, this architecture uses the tree definitions module, that defines the structures used for representing the tree, the parser module, which creates the abstract syntax tree, and the execution module. All of these modules must be maintained in precise synchrony, which impacts program maintenance. An abstract syntax tree consists of a hierarchy of nodes which correspond to the principal features of the script. It is quite easy to build an abstract syntax tree at parse time, since it represents nothing more nor less than a summary of the parse. Done correctly, an abstract syntax tree is a faithful representation of the original script. The tree has an advantage over the raw script, however, in that it can be easily traversed from the top down. Evaluation of expressions and execution of statements can then be implemented by simple recursive functions. If a single script must be executed several times, execution from a tree has noticeable performance advantages over interpreters which execute as they parse, since the script need only be parsed once.
3. Direct Compilationdci: Direct Compilation Interpreter ReferenceA second technique for decoupling parsing from execution is to create a simple bytecode interpreter and then generate bytecode as the script is parsed. The script can then be executed by running the bytecode interpreter on the compiled code. The bytecode can be thought of as representing instructions for a "virtual machine". Like execution from an abstract syntax tree, this approach, illustrated by the "direct compilation interpreters", dci, appears superficially to be more complicated than direct execution, since it requires three modules rather where the direct execution interpreter had only two. For many problems, however, it can be the most suitable approach. If a script must be run a large number of times, compilation to bytecode provides significant improvements in execution time compared to the direct execution approach. The parser itself is noticeably simpler and easier to maintain or extend. These advantages are counterbalanced, however, by the need to create and maintain a second support module which must be coordinated with the other two modules.
4. Tree Compilationastci: Tree Compilation Interpreter ReferenceJust as direct execution at parse time imposes difficult constraints on parsing, direct compilation at parse time can sometimes impose difficult constraints on the bytecode interpreter. It is quite easy, for example, to compile directly for a bytecode interpreter that uses a simple accumulator stack architecture. It is not so easy to compile at parse time for a register based architecture, nor is it easy to even do simple optimizations, such as reducing constant expressions at compile time, with such an approach. These difficulties can be easily overcome by the most powerful of the four architectures, compilation of bytecode from an abstract syntax tree. Because it is easy to pass over the tree a number of times, it is possible to do much more sophisticated compilation than is possible when compiling directly at parse time. Interposing the creation of the abstract syntax tree, of course, adds to the total amount of code necessary to implement the interpreter, and, of course, increases maintenance problems. These disadvantages are often offset by the potential for substantially improved performance. This approach is illustrated by the abstract syntax tree interpreters, astci. For simplicity, these compilers use the same bytecode interpreter as the direct compilation example, although it would be straightforward to compile bytecode for a more efficient virtual machine. However, to illustrate the increased versatility of working from an abstract syntax tree, it also incorporates some simple compiler optimizations. These optimizations are controlled by the OPTIMIZE switch, so they can be eliminated in order to compare the generated code to that created by the direct compilation interpreter.
|
| Table of Contents | | | Parsifal Software Home Page |
|---|