|
XIDEK
|
Frequently Asked Questions
What is XIDEK?The XIDEK kit provides technical guidance and source code so that you can readily design and implement an interpreter according to your own requirements. You may need, for example, to create a special interpreter for a domain specific language, script language, or other "little language".XIDEK can save you weeks or months of work. It gives you parsers, support modules, explanations, examples, organization and a framework upon which you can build.
Who can use it?XIDEK is intended for software developers who want to develop an interpreter to support a script language, "little language", or domain specific language, or perhaps would just like to study some examples of the use of the AnaGram LALR-1 parser generator.
What's in the kit?
What are CLL and PLL?The kit implements two baseline languages: a C-like language, CLL, and a Pascal-like language, PLL. Both languages include control structures such as if statements, while statements, and for loops. In the directory tree, cll and pll subdirectories are used to keep language specific files separate.
What are dxi, dci, astxi, and astci?These are shorthand for the four interpreter architectures illustrated by the kit:
There's a lot of material here. Do I have to look at all of it?If you have a specific application in mind, you could first read about the four interpreter architectures covered in the kit and select the one most appropriate. Then focus on the baseline version of that architecture for either CLL, the C-like language, or PLL, the Pascal-like language, preferably beginning with CLL.The interpreters pertaining to language extensions will be of interest when and if you wish to make changes.
What's the easiest way to familiarize myself with the interpreters in the kit?For a general approach, you should start with the baseline interpreters. The language dependent code for these is found in the cll\base and pll\base directories. The language independent code is in support\base. A simple driver program, driver\demo.cpp is used for all the interpreters in the kit.To understand all of the interpreters in the kit, it is sufficient to look at just the four baseline CLL interpreters, in order to get an understanding of the four architectures used in the kit:
The rest of the interpreters in the kit are identical to one or the other of the baseline interpreters except for the addition of small amounts of code in order to add extra features. Detailed documentation of these changes may be found here .
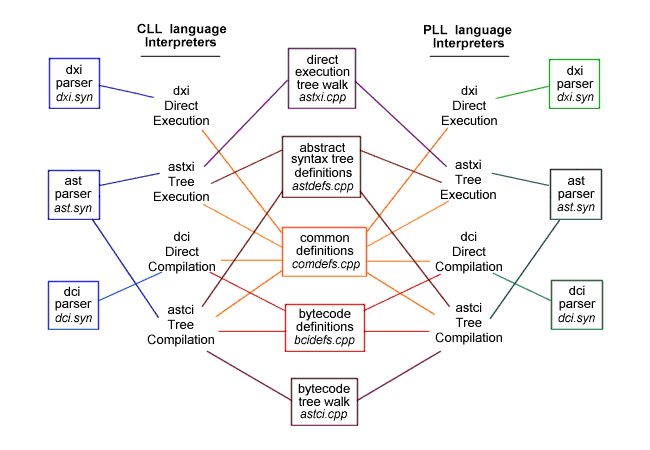
Isn't there a huge amount of code in this kit?You might think that forty-eight separate interpreters would require a huge amount of code, but that is not the case. In fact, because of the way the interpreters share code, the amount of distinct code is actually quite small.First, the kit consists a set of functionally equivalent baseline interpreters and corresponding sets of functionally equivalent extension interpreters. Each of these sets of extension interpreters has been created by adding just a small amount of code to the modules that comprise the baseline interpreters. Thus any extension interpreter can be understood simply by comparing it, module by module, to the corresponding baseline interpreter. To help, the kit contains reference documents which describe the changes in detail. Second, the kit supports two different languages. Although the languages are syntactically different, they are nearly identical functionally. Thus, for any given interpreter architecture, the parsers required by the two languages are remarkably similar. The syntactic details are different, but the support code, the reduction procedures and embedded C are nearly identical. Similarly, all the parsers for a given language use the same base grammar, and differ largely in their reduction procedures. Reference documents contain detailed descriptions of the differences between the basic language syntax and the actual parsers. Third, the kit supports four different interpreter architectures. These architectures require symbol table support. A single module, the common definitions module, provides this support for every baseline interpreter. Similarly, the bytecode definitions module and the abstract syntax tree definitions module are shared as needed. Perhaps the most surprising fact is that the tree walk modules are the same for both languages in the kit. Finally, the simple demo program in the kit, driver\demo.cpp, is used for all the interpreters. For the details of how the modules are shared, please refer to the diagram found here.
Just how is code shared among all these interpreters and languages?
The kit actually contains one
set of eight baseline interpreters and five sets of extended interpreters.
Each set of eight interpreters consists of interpreters that implement
two languages using four
different architectures. All the interpreters for a given language are
functionally equivalent.
A set of eight interpreters requires only eleven modules which are shared as shown below:
Each set of extension interpreters has the same modular structure as the baseline interpreters. In fact, the modules for each extension are exactly the same as the baseline modules with small amounts of added code. The above diagram does not even show all of the code sharing among the interpreters, because they all use essentially the same syntax file with minor variations. And the two baseline languages have many common elements. The interpreters also are implemented as functions which all have the same interface. And they share a simple demo program, driver\demo.cpp.
Why should I build my own interpreter?There are a lot of interpreters available, awk, perl, and python, for example. Why make another?It isn't that you want an interpreter just for its own sake. It's that you wish to implement a customized language that suits the particular needs of a particular user base. Often, the user base does not consists of professional programmers, but rather people who are expert in a particular problem area. They wish to have a language that allows them to state problems in a language that is congenial to their area of interest and that can be easily read and understood by their colleagues. Another reason might be that you have a program that needs to be able to initialize variables used by the interpreter and access results when the interpreter has finished its script. In other words, your program uses user-written scripts to customize itself.
Can I embed an interpreter in my own program?Yes. All the interpreters in the kit are implemented as simple functions with the same function prototype:Value interpret(const char *script, Dataset &dataset);The Dataset object, dataset, is the symbol table to be used by the interpreter. It contains the names of variables and their values. As the interpreter encounters new variables while running the script, it adds their names and values to dataset. The values of variables in dataset can be initialized by the host program before the script is executed and can be accessed after the script completes execution. Thus it is easy to use a script to customize a more general program.
Why should I use this kit?Because it's a practical way to get a reliable, maintainable interpreter written and working quickly. There are lots of other ways you could proceed. Most of them, however, will require duplicating a lot of tested code that already exists in this kit and that is available for re-use in your interpreter.
Can I use this kit to write a translator instead of an interpreter?Yes. If you need to generate code in a language such as C, you could use the tree compilation interpreters as a guide.Instead of generating bytecode, you would simply emit C code instead. If you are using a variant of the CLL language, you might be able to introduce substantial simplifications by adding a second character pointer to the FileLocation to track the next location in the script for each rule. This way, the code generator would know the extent as well as the location of any construct in the script. Using this information, constructs which are invariant could simply be copied verbatim from the input script, preserving comments.
Are there any restrictions on using this kit?XIDEK itself is being released under a simple license which allows both commercial and non-commercial use. A copy of the license may be viewed here.A distribution that contains modified syntax (.syn) files will require a valid license for the AnaGram Parser Generator in order to generate the corresponding parser files. However, you do not need to use AnaGram to understand the discussion of the different approaches to interpreter architecture. Nor do you need AnaGram to use the syntax (.syn) files in the download as is, since the parsers produced by AnaGram from these syntax files are included in the download. If you wish to try the kit with a modified syntax file, a free trial copy of AnaGram is available for immediate download at www.parsifalsoft.com.
What steps should I take to create my own custom interpreter?Follow these steps and you can quickly develop your own working interpreter, built to your own specs but with powerful standard language features like ifs, whiles, and arithmetic expression evaluation already built in from the start. What's more, you'll always be in the position of having a working program to demonstrate that your project is on track.
What exactly is a parser?A parser is a program module that scans an input file, a script file, for example, and decomposes it into its constituent parts and then processes the parts in some suitable manner. The XIDEK kit contains just three baseline parsers for each of the two baseline languages it implements, since the ast parser is shared by both the astxi and astci baseline interpreters:
How do I build a parser?It's simple. The kit uses parsers built by the AnaGram LALR-1 parser generator from syntax (.syn) files. Just use AnaGram's "Build Parser" command and select a .syn file to build a corresponding parser. Actually two files will be created, a header file and the actual parser file - the configuration sections of XIDEK's .syn files are set up so that these will have the same name as the .syn file and the extensions .h and .cpp respectively.You do not need AnaGram to use the syntax files in the download as is, since the parser files produced by AnaGram from these syntax files are included in the download. If you do not have a licensed copy of AnaGram and wish to try out a modified syntax, you can download a free trial copy from the Parsifal Software website: http://www.parsifalsoft.com. Note that distribution rights for parsers built with a trial copy are limited. See the kit license for details.
Why do I need a parser generator?There are several reasons. The first is that writing a parser by hand is enormously difficult, even for simple languages. The reason is that how you handle a specific piece of input is contingent on previous input in very complicated ways. Keeping track of these contingencies is not easy.The second reason is that, for all its complexities, parsing is one of the few branches of programming for which code can be generated algorithmically from a problem description. Furthermore, the generated code can be proved mathematically. A parser generator is simply a program which implements these algorithms to create a C/C++ parser module from a language specification, called a syntax or grammar.
If parser code can be generated algorithmically, why can't I just implement the algorithms by hand?You certainly could. However, if you ever have to make any changes to the language you're interpreting, you'll have to reimplement the algorithms, or understand them well enough to make the correct changes. This is not a trivial problem.Another reason for using a parser generator is that when you do things by hand, there's always a probability of making a mistake. Such mistakes may not be readily apparent and you face a significant possibility of distributing error ridden code to your users. When you use a parser generator you guarantee that the language your parser interprets is the language you have specified in your syntax file. Yet a third reason is that a parser generator can detect possibly ambiguous constructs in your language. If there actually is an ambiguity, and you've implemented your parser by hand, you may find out about it only when you get a complaint from one of your users. At that point, you not only have to identify the nature of the ambiguity, but you have to modify your parser to eliminate it. The AnaGram parser generator has powerful tools to help you identify ambiguities in your grammar, saving you from this sort of difficulty.
Don't I need a lexer to go with the parser?With many parser generators, such as YACC or Bison, a preliminary input process known as a "lexer", or lexical analyzer, is usually required. Such a separate input process adds substantial complexity to an interpreter. The AnaGram parser generator provides several features which make the use of a separate lexical analyzer unnecessary for many parsing applications. |
| Table of Contents | | | Parsifal Software Home Page |
|---|